




Jungroo Learning is a B2B SAAS based EdTech start-up that helps educators and organizations understand and chart their student’s journey at a microscopic level through an AI-powered Adaptive Engine.
Jungroo is a GPS for educators and education organizations. Jungroo locates the learner precisely and creates the shortest learning path to mastery for them. Their adaptive platform lets organizations create adaptive content or make their existing contents adaptive.
For more information about Jungroo visit www.jungroo.com
This article by our CTO and cofounder Cibe Hariharan talks about the technology behind Jungroo’s adaptive engine and how Jungroo has overcome some of the challenges that the current approaches in adaptive learning faces.
The Challenges
- Predict the student’s knowledge state with minimal interactions with the student.
- Predict his/her shortest learning path to mastery.
Existing solutions
Existing approaches used for adaptive learning are based on cross-sectional and longitudinal data of students behaviours.
Cross-sectional data
Cross-sectional data is the data that is collected by observing multiple students’ behaviour at the same time. It’s an atemporal data. An example of such data would be the summative assessment data of multiple students at the same time.
Longitudinal data
Longitudinal data is the data that is collected from student behaviours at different points in time. An example of such data would be the formative assessment data of the same student at different points of time.
Models built on the cross-sectional data
- Fixed Questions with Item Response Theory
- Adaptive testing with Item Response Theory
Models built on the longitudinal data
- Bayesian Knowledge Tracing
- Probabilistic Graph Models
Cross-sectional data models
1) Fixed Questions with Item Response Theory (IRT)
Fixed question sets are given to the students. An IRT model relates a student’s ability with the probability of answering a question correctly, given the question’s difficulty.
Why is Fixed Questions IRT used?
Consider a scenario where two students A and B, score the same mark (say 8/10). Student A answers two easy questions incorrectly and student B answers two difficult questions incorrectly. In traditional grading approaches, both the students get the same marks and are treated to be at the same level. Some engines use the (Question, Response) pairs to create a model (IRF function). The IRF function outputs the probability that a person with a given ability level and difficulty level will answer correctly.
What are the limitations?
Fixed questions tests are “One size fits all”, making the students in both extremes, high achievers/late bloomers, not interested in the test.
2) Adaptive testing with Item Response Theory
Adaptive testing is used to find the student’s ability. The system estimates the ability level of students using IRT and subsequent questions are selected based on the candidate’s estimated ability.
Why is adaptive testing used?
If a candidate answers a question incorrectly, he/she will be provided with an easier question, leading to better engagement. Estimation is faster and more accurate than the fixed question IRT.
What are the limitations?
- It will work only if all the questions can be calibrated on the same scale i.e. difficulty level. Assume two unrelated questions Q1 (Multiplication) and Q2 (Subtraction) with different difficulty levels D1 and D2 are present in the assessment. Also, Q1 is difficult than Q2 (D1 > D2) If the student is able to answer Q1 and some questions that are difficult than Q2 correctly. Then the system built on this data predicts that the student can answer the easier question Q2. This might be unlikely to happen in reality since the easier question (Subtraction) is not related to questions with higher difficulties (Multiplication). Student knowing Q1 (Multiplication) might still not know Q2 (Subtraction).
- It can’t diagnose why the student can’t answer questions beyond specific difficulty levels.
Longitudinal data models
1) Bayesian Knowledge Tracing
It uses a history of interactions (Question response pairs) of all students to build an ability model for the examinee. The model is updated after every interaction. There are variants of Bayesian Knowledge Tracing created using deep learning algorithms called Deep Knowledge Tracing that have similar performance on the data.
Why is Bayesian Knowledge tracing used?
Bayesian Knowledge tracing predicts the performance on future interactions that are about to happen. This data can be used in recommendations.
What are the limitations?
Sufficient data about a student is needed to do an accurate prediction. The initial set of interactions can be time-consuming and can make a student less engaged with the system.
2) Probabilistic Graph Models
Bayesian networks are widely used PGMs in modelling student behaviour. They are used to learn relationships between the concepts from the data. Given the knowledge state (set of concepts mastered), they can predict how the students might do in related concept, which helps in recommendations.
What are the limitations?
It suffers from a cold-start problem. Ample student data is needed to do an accurate prediction. If the Initial set of interactions are irrelevant to learner’s level, it can make him/her lose interest thereby leading to inaccurate data.
Limitations with existing approaches
- Learning gaps across grades are not found. Example, a sixth-grade student learning algebra might have a learning gap in multiplication, which is taught in third grade.
- Learning gaps across domains are not found. Example, a student who can’t answer addition of unlike fractions in fractions domain might have a learning gap in multiplication domain
- The shortest path to mastery is not found using any of the approaches because Longitudinal data models that are used in recommendations require more student interactions to perform accurate predictions. Inaccurate recommendations can make the student less engaged.
Jungroo has solved the problems in the existing approaches and has come up with a solution that addresses these problems. Let’s look at it.
Jungroo’s approach in predicting the knowledge state
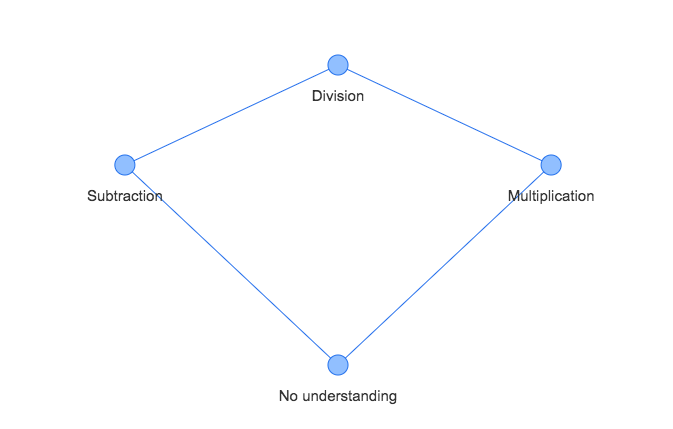
Concepts C = { Subtraction, Multiplication, Division}
Dependencies D = {{Subtraction, Division}, {Multiplication, Division}}
Knowledge Graph K: Set of concepts and dependencies between them. It is created by an expert. For easier understanding, consider an example of small knowledge graph containing three concepts with two dependencies.
The following figure describes the Knowledge graph K



 Madhav Bissa
Madhav Bissa Supriya Samuel
Supriya Samuel

 Raj Shekhar
Raj Shekhar Tarun Kumar
Tarun Kumar{kind=link}
{kind=link}
{kind=link}
{kind=link}