


ML Ops is a set of practices that combines Machine Learning, DevOps, and Data Engineering, which aims to deploy and maintain ML systems in production reliably and efficiently.
source https://ml-ops.org/img/mlops-loop-en.jpg
The Deployment of machine learning models is the process of making models available in production to meet intended business goals. It is the last and most challenging stage in the machine learning lifecycle. Machine learning Architecture in production requires multiple components to work such as infrastructure, applications, data, documentation, and configuration.
You will also have to remember that you’re putting a software application into production, which means you’ll have all the requirements that any production software has, including:
- Scalability: How the solution behaves faced with increased workload
- Consistency: Repeatability and reliability i.e ability to produce the results and resilient to errors
- Maintainability: Reusability and Modularity
- Flexibility: Adapt to changes
- Reproducibility: Specific to Data science
Architectural best practices are important as building a working pipeline without them is easy but maintaining them over time, updating models, redeployments will eventually fail.
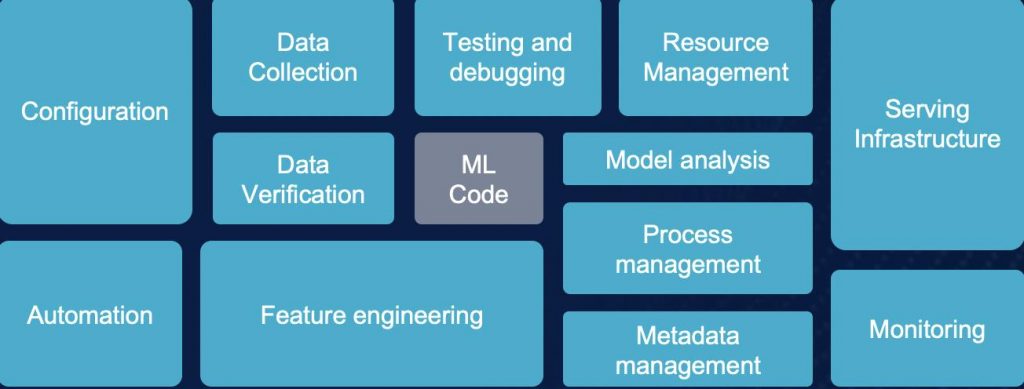 Fig 2. Steps of MLOps Lifecycle Management
Fig 2. Steps of MLOps Lifecycle Management
Where Data Science meets Engineering
- Journey from Research to Production essentially its more of deploying a pipeline than just the model
- Components from Research namely Feature Engineering and selection along with model take the journey to production
- Automation of all stages of the workflow and any manual intervention like SSH, manual scripts leave scope for error.
- Docker as a container is the choice as the primary unit of deployment
- An Orchestrator and optionally a model lifecycle management setup
- Choice of PAAS (Platform as a Service) and IAAS (Infrastructure as a service) is split across different cloud providers /platforms
Challenges in ML deployment and Model life cycle management
As Machine learning models get embedded in software products and services, the best practices and tools employed with software delivery also apply to ML deployment, thereby minimizing technical debt while employing best practices to test, deploy, manage and monitor ML models.
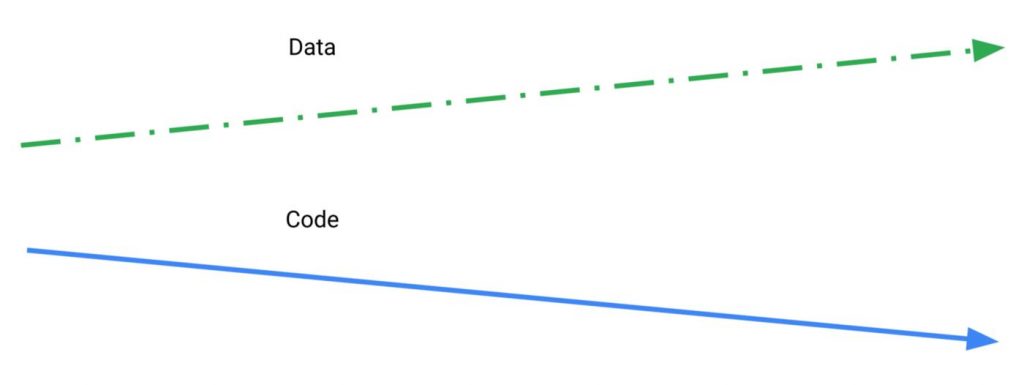
Traditional DevOps allow developers to abstract accidental complexity and let developers concentrate on actual problems, using tools automation, and workflows but we can’t we simply keep doing the same thing for ML as ML is not just code, it’s code plus data. An ML model, the artifact that you end up putting in production, is created by applying an algorithm to a mass of training data, which will affect the behavior of the model in production. Crucially, the model’s behavior also depends on the input data that it will receive at prediction time, which you can’t know in advance
It is of course possible that a single person might be good enough at all of them, and in that case, we could call that person a full ML Ops Engineer. But the most likely scenario right now is that a successful team would include a Data Scientist or ML Engineer, a DevOps Engineer, and a Data Engineer.
The Challenge
- Needs coordination between Data Scientists, IT Teams, S/W Developers, and business
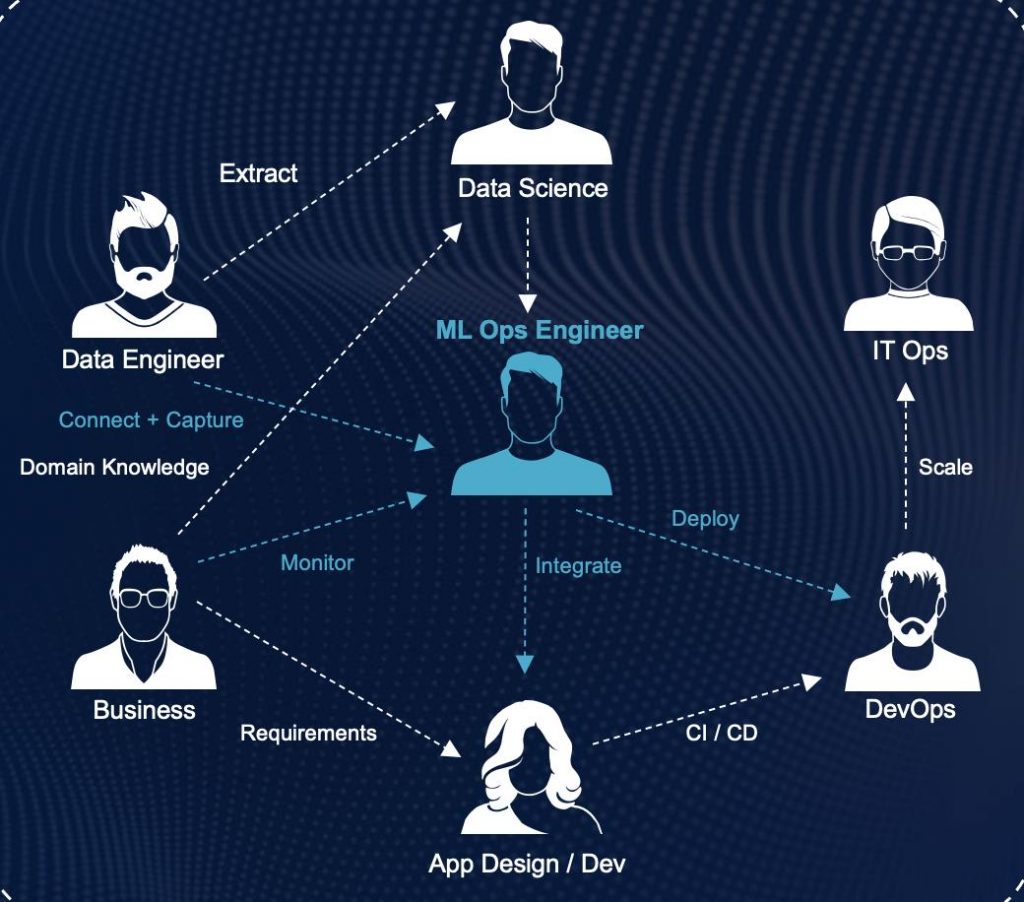 Fig 3. Interaction of stakeholders in Machine Learning Lifecycle
Fig 3. Interaction of stakeholders in Machine Learning Lifecycle
Traditional dev-ops employ rapid delivery cycle in minutes but differ in its application to ML in a fundamental way where it consists of code with data
- System Complexity involving a large spectrum of skills
- Need for reproducibility (Versioning everywhere)
- Managing configuration model hyperparameters, requirements, data sources can all be changed via configuration
- Data dependencies i.e., data sources can change suddenly
- Unit and Integration testing input feature code, Model specifications code
- AB testing /canary release to a limited audience and blue-green deployments
- Model Quality validation before serving
- Model monitoring
Reproducibility in Machine Learning Pipelines:
In traditional software, system behavior can be effectively captured by source code versioning as code defines all behavior. In ML there are two other aspects to be tracked to effectively capture system behavior i.e. model version and the data on which the model is trained, and some meta-information like training hyperparameters. Models and metadata can be tracked in a standard version control system like Git, but data is often too large and mutable for that to be efficient and practical.
It’s necessary to version data and tie each trained model to the exact versions of code, data, and hyperparameters that were used. The ideal solution would be a purpose-built tool, but so far there is no clear consensus in the market and many schemes are used, most based on file/object storage conventions and metadata databases.
There is no consensus on any purpose-built tool and many approaches are used with most based on metadata databases or file storage conventions
The challenge to reproducibility is while the code is crafted in a controlled environment the real-world data comes from a source of entropy and there are bound to be inconsistencies. The challenge of an ML process is to create a bridge between these two planes in a controlled way.
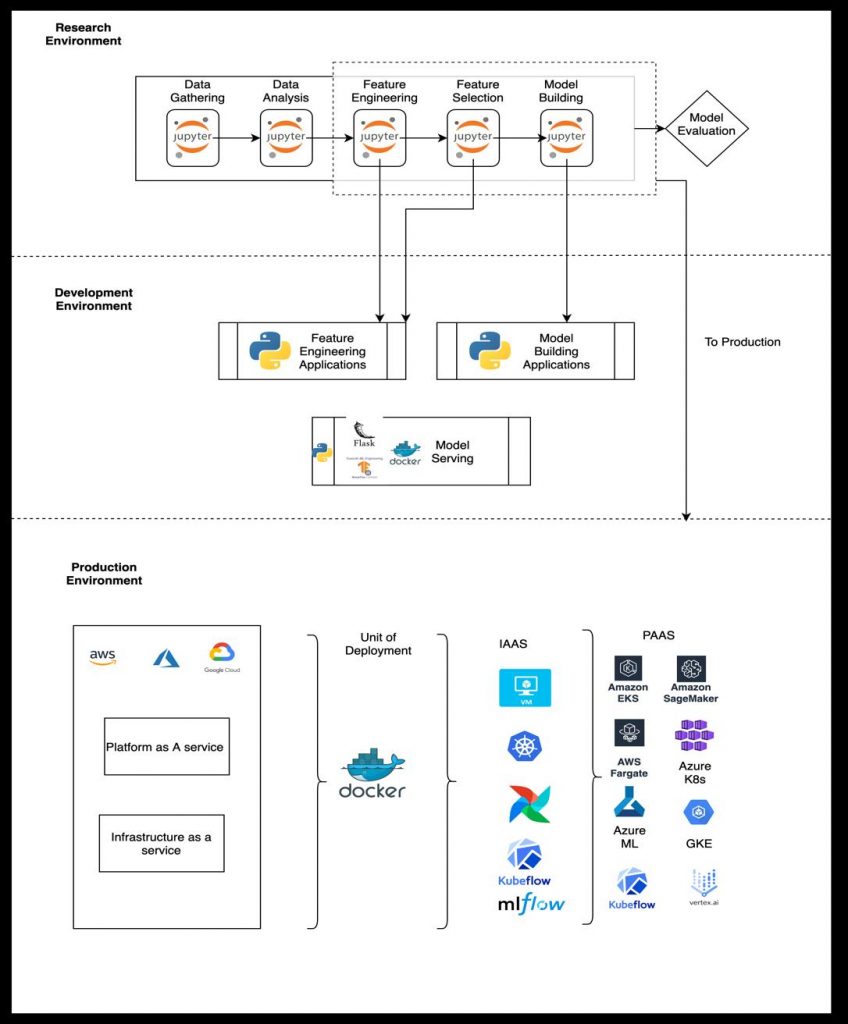
MLOps in building ML pipelines
An ML pipeline consists of a series of stages. As ML models need data transformation a data pipeline creates a series of repeatable transformation nodes consisting of data pre-processing, aggregations, etc. This is essentially a data pipeline with data engineering steps where a series of steps are applied between the data and its source. Many tools help manage the run of these pipelines. This approach promotes code reuse, runtime visibility, management, and scalability.
- Since ML training is also assumed as a series of data transformations, the ML stages can be added to a data pipeline to turn it into an ML Pipeline. Most models will need two versions of the pipeline i.e. for training and one for scoring/serving. The data pre-processing and feature engineering stages will be migrated from research to development to production for both training and scoring /serving
- Models development /training is essentially an experiment-driven and tracking these experiments will require specific tooling to track the models, data, and hyperparameters
- The above two steps are essential in building reproducible pipelines across environments i.e from research to production.
 Although documenting an incredibly fragmented problem space in terms of approach and tooling would not be possible in entirety and it is very hard to generalize. We can have approaches ranging from cloud platform offerings on all major cloud providers to entire stack put together with opensource tooling, but by now we have documented the contours of the landscape to develop a brief understanding of an MLOPS road map.
Although documenting an incredibly fragmented problem space in terms of approach and tooling would not be possible in entirety and it is very hard to generalize. We can have approaches ranging from cloud platform offerings on all major cloud providers to entire stack put together with opensource tooling, but by now we have documented the contours of the landscape to develop a brief understanding of an MLOPS road map.



 Madhav Bissa
Madhav Bissa Supriya Samuel
Supriya Samuel

 Raj Shekhar
Raj Shekhar Tarun Kumar
Tarun Kumar{kind=link}
{kind=link}
{kind=link}
{kind=link}